








How to sync and query Supabase data in PostHog

Contents
Combining your database and analytics data is a powerful way to understand your users. Supabase is a popular choice for handling that app data, as it provides a database, auth, storage, and more all-in-one.
Thanks to modern advances in enterprise synergy™, we can link and query your Supabase data in PostHog using our data warehouse. This tutorial shows you how to do that and provides some example insights you can create with the data afterward.
Linking Supabase data to PostHog
Note: We currently don't support connections using IPv6, therefore, you will need to enable IPv4 connections to your database. If you have enabled IPv4 connections, you can connect directly to your database with a simple connection string. Alternatively, you can use Supabase's session pooler connection. The shared pooler is IPv4 compatible by default, and it is included in new Supabase projects for free.
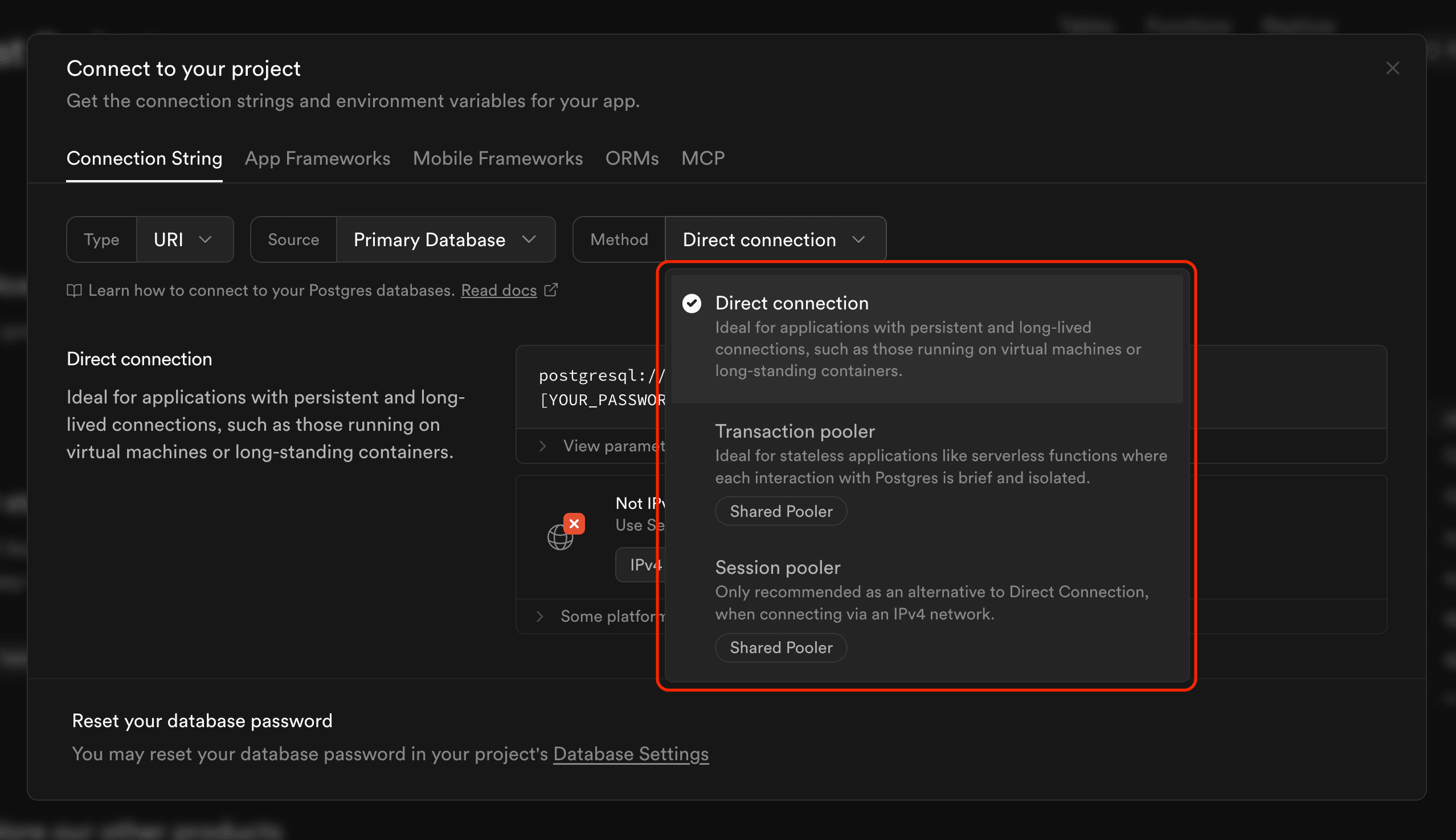
To start, you need both a Supabase and PostHog account. Once you have those, head to PostHog's data pipeline sources tab and:
- Click New source
- Choose the Supabase option by clicking Link.
- Go to your Supabase project settings and click Connect in the top nav bar.
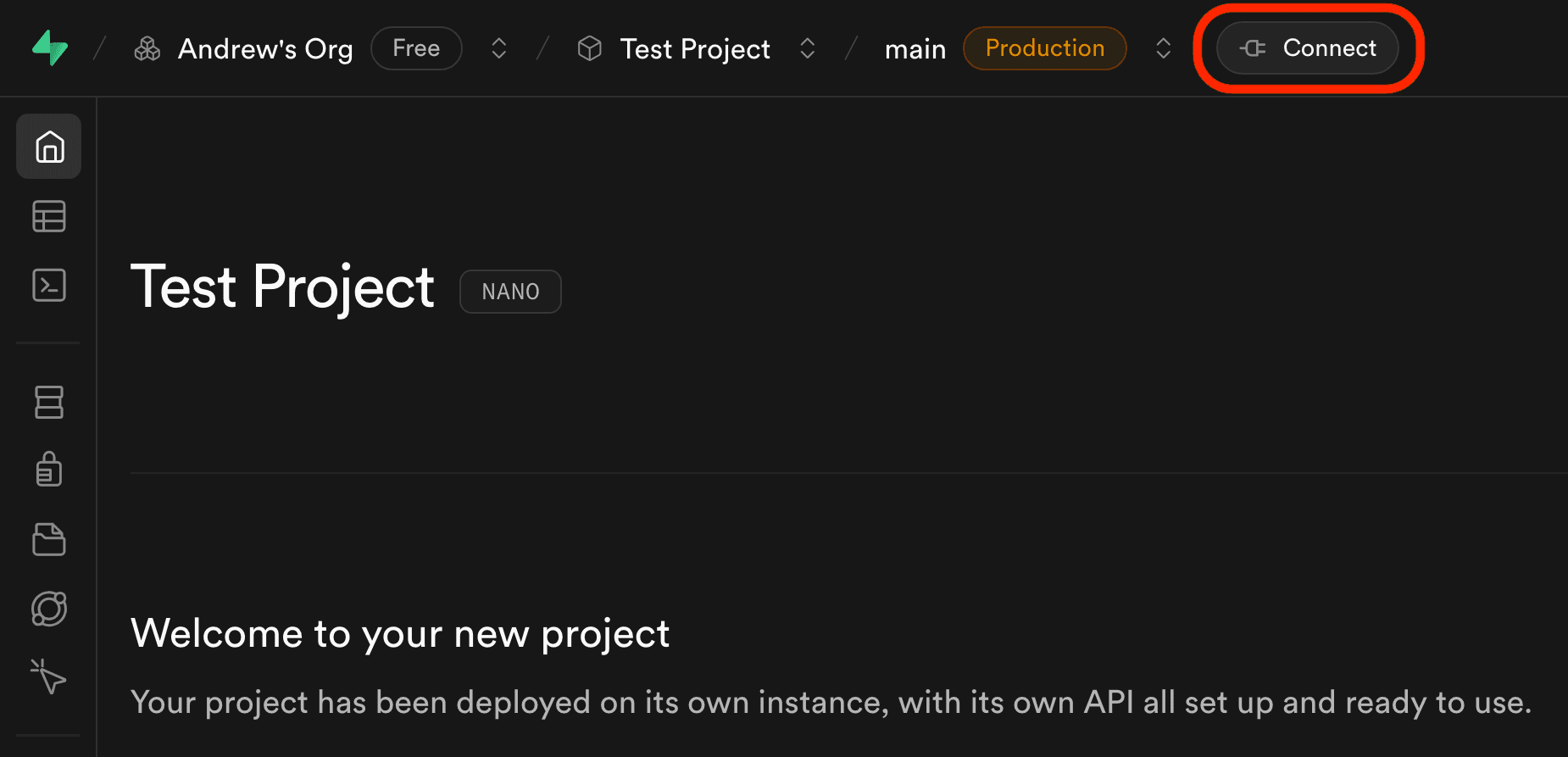
- Copy the Supabase connection string shown.
- Paste the value into the PostHog data warehouse
Connection stringfield.- Supabase will not include your password in the connection string. You will need to replace their password placeholder manually.
- If you've forgotten your Supabase database password, you can reset it.
- Fill in the schema name that you want to sync. Typically, this is just
public. - Click Next.
- Select the tables you want to include, how you want to sync them, and click Import to start syncing.
Once it completes, you can then query the data in PostHog.
Querying Supabase data in PostHog
You can query your Supabase data using SQL insights. This enables you to combine it with your PostHog usage data.
Visualizing the count of objects over time
You can use trends to visualize your data. For example, to visualize a count of objects over time:
- Create a new insight.
- As a series, search for
postgresand select your table. For us, that ispostgres_newsletters. - Ensure your ID, distinct ID, and timestamp fields are correct and press Select.
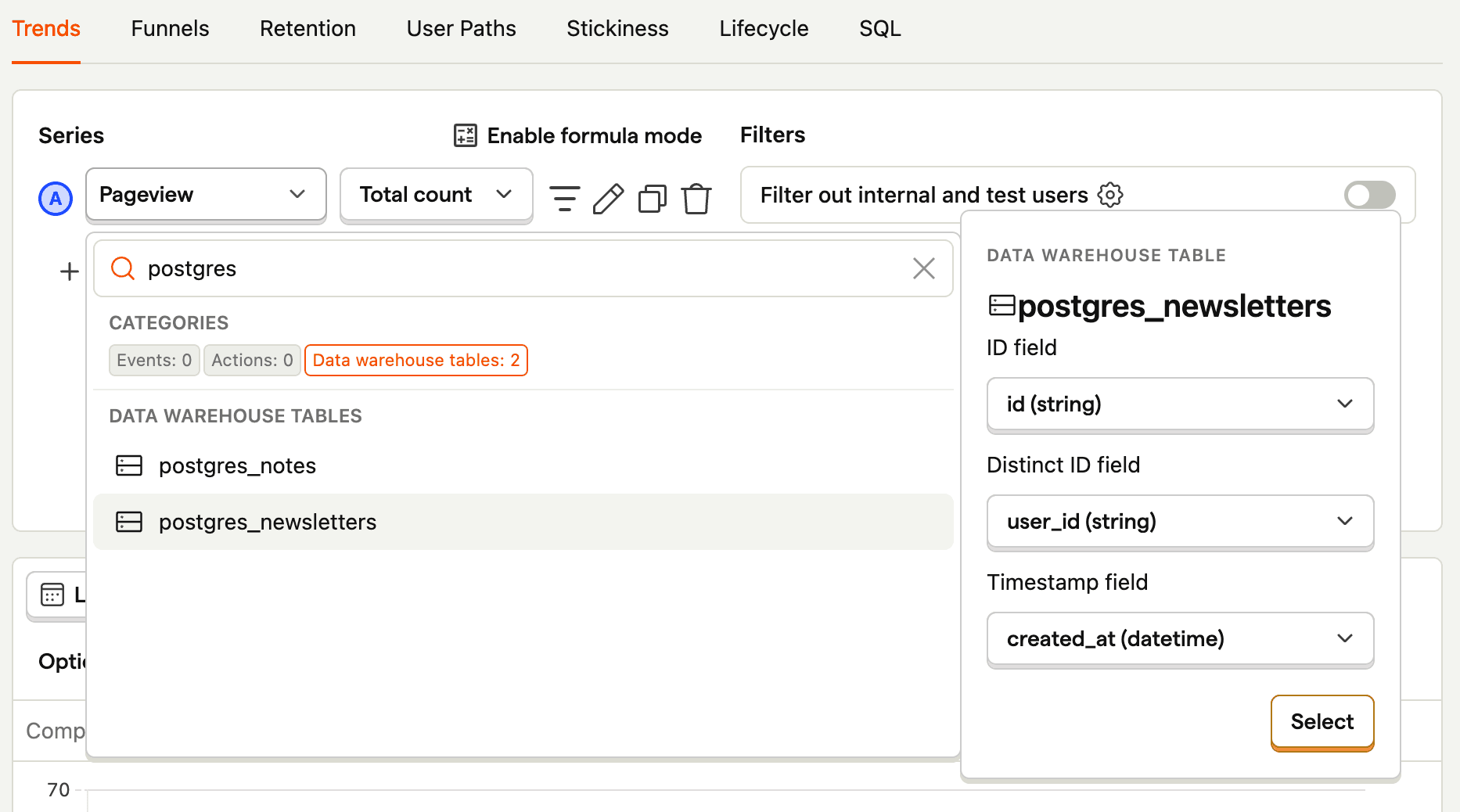
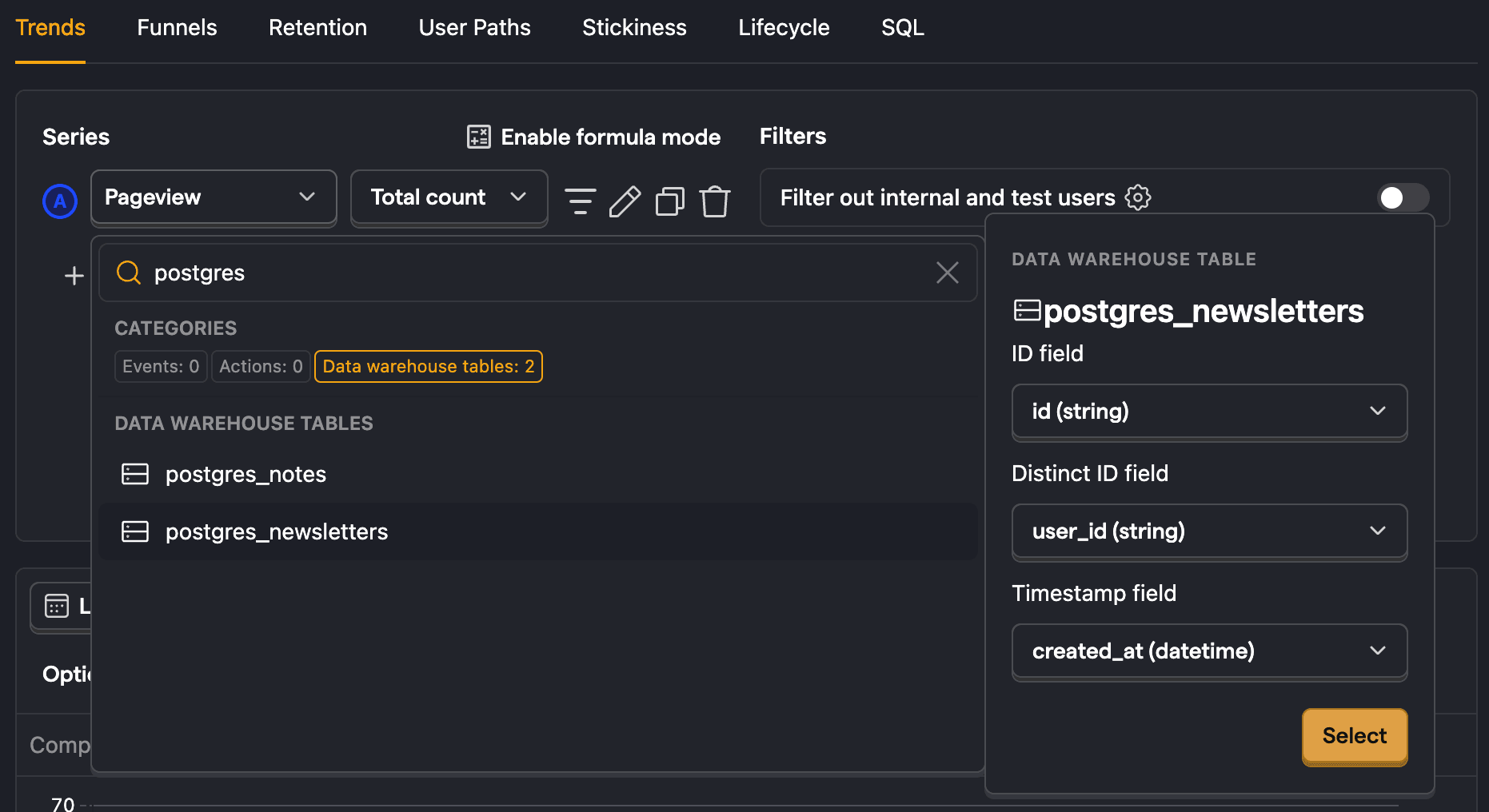
This creates a trend of the count of the objects in your table over time. You can then modify it using filters, visualization options, and breakdowns. For example, to break down by user_id, click Add breakdown, select the Data warehouse properties tab, and then choose user_id. To visualize this nicely, you can change the line chart to a total value bar chart.
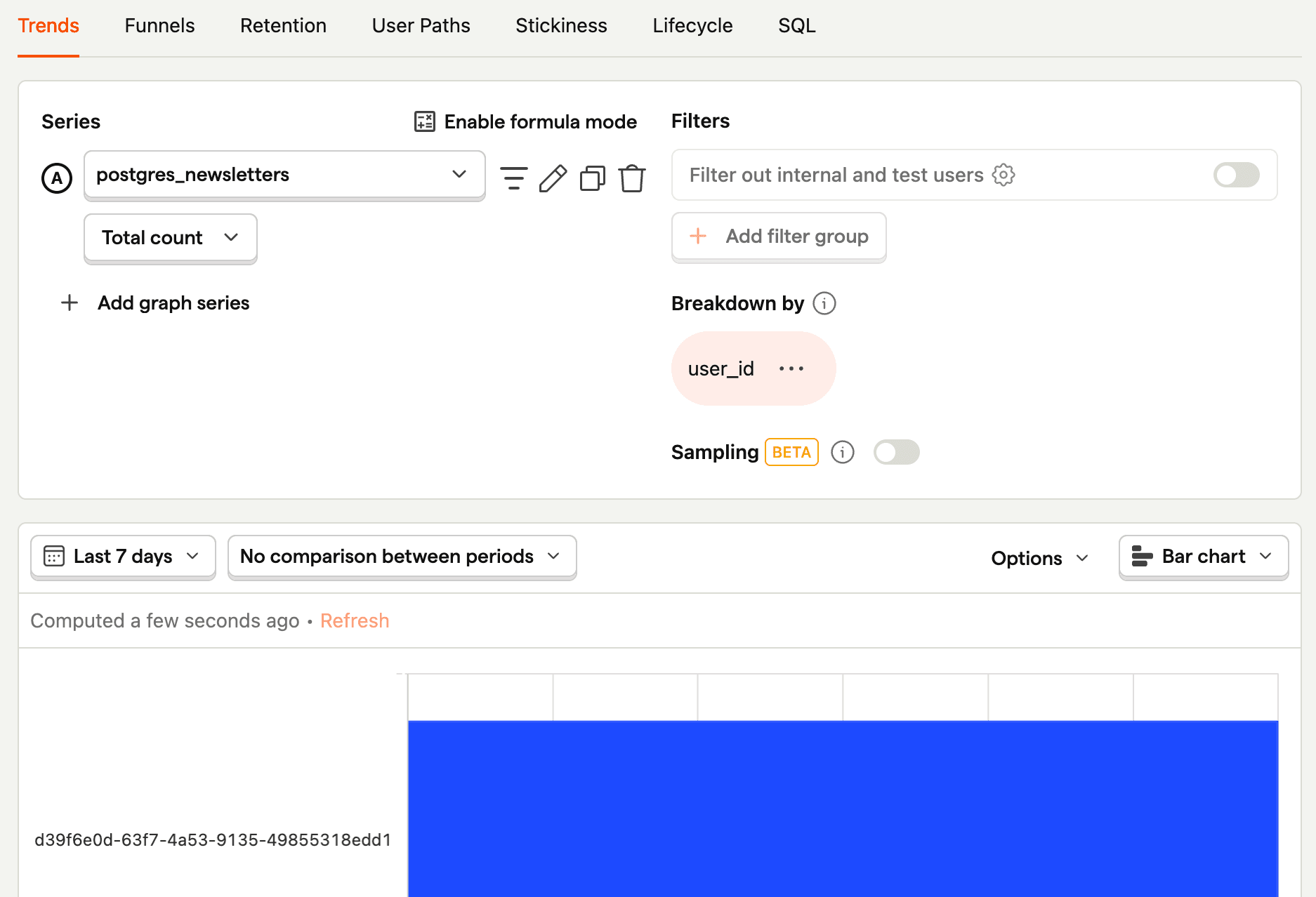
Combined user overview
Linking your Supabase user table (under the auth schema) enables you to get an overview of user data across both sources. This does require you to add a table prefix like supabase_ if you already have a Postgres source linked.
To create this overview, create a new SQL insight that:
- Gets
email,last_sign_in_at,created_atfrom Supabase'susertable - A count of events from PostHog's
eventtable - Join the tables using
emailanddistinct_id
Altogether, this looks like this:
We could also PostHog person properties or a Supabase table to these by joining more tables to this query.
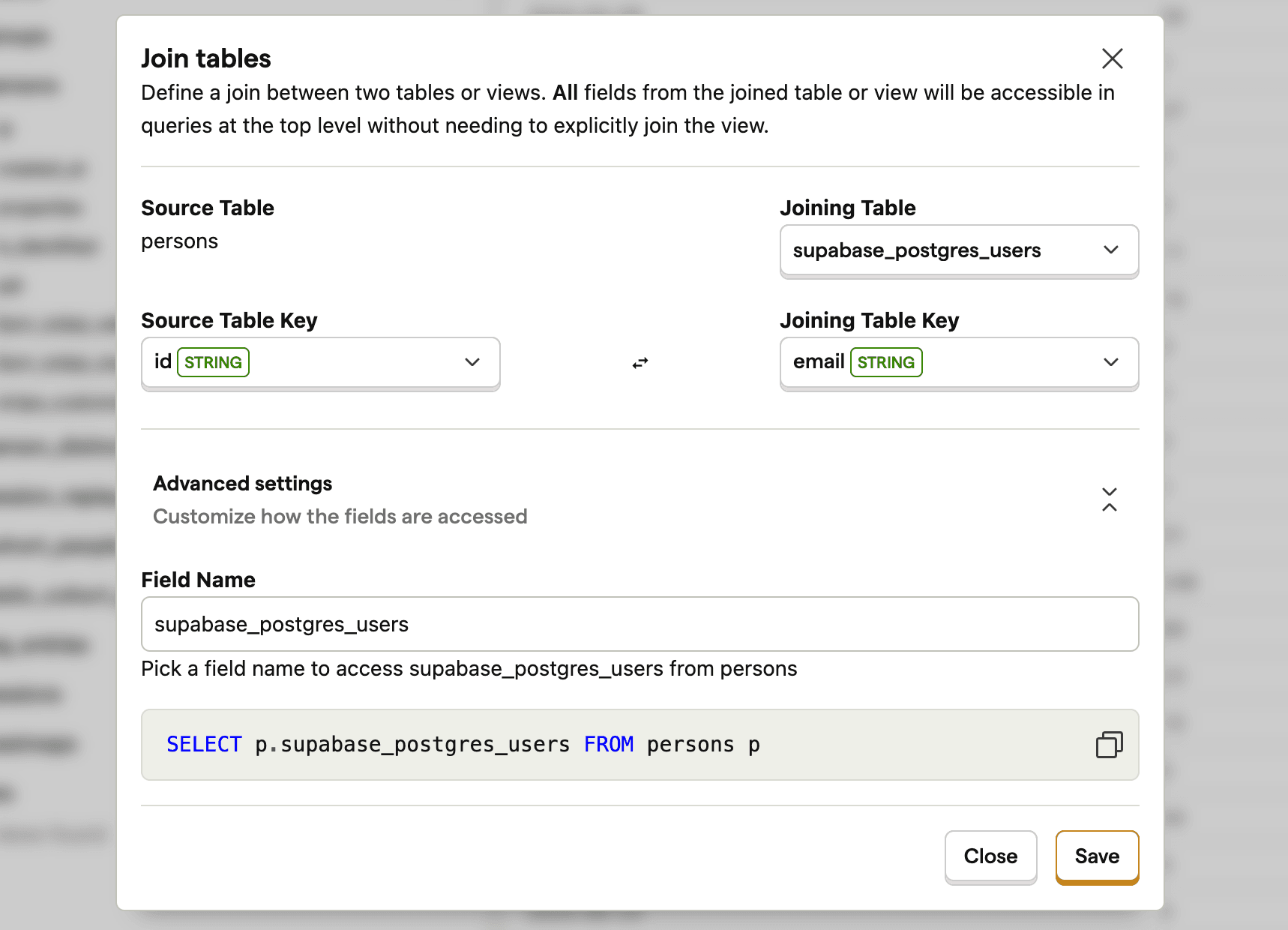
Tip: You can also set up a join between PostHog's
personstable and your Supabaseuserstable. Go to the data warehouse tab, click the three dots next to thepersonssource, and click Add join. This enables you to use Supabaseusersdata wherever you can use persons.
Usage by paid users
Similar to the last query, we can get a list of paid users from Supabase by filtering for users with a paid column (or equivalent) set to true. We can then use this list to analyze their PostHog usage.
If your payment details were on another table, you could also join that table.
Querying observability stats
Supabase also captures observability data we can query if you link the pg_state_statements table from the extensions schema.
An example of a query you could get from this is p95 total execution time along with the median rows read:
Another example is the most time-consuming queries:
One more for good luck, this gets queries with high variability:
Further reading

Subscribe to our newsletter
Product for Engineers
Read by 100,000+ founders and builders
We'll share your email with Substack
PostHog is an all-in-one developer platform for building successful products. We provide product analytics, web analytics, session replay, error tracking, feature flags, experiments, surveys, LLM analytics, data warehouse, CDP, and an AI product assistant to help debug your code, ship features faster, and keep all your usage and customer data in one stack.